Finding Patient Zero With Security Analytics
Learn how prevalence-aware security analytics detect patient zero, the earliest compromise in a targeted attack, before SIEM-based detection can catch up.

Security teams can usually confirm compromise once an attacker leaves a trail that threat intelligence providers have already documented. The harder problem is finding the first foothold in a targeted campaign, before the attacker's infrastructure or techniques become widely known. That first foothold is patient zero: the earliest compromised identity, endpoint, workload, or application session in your environment, and the point where defenders have the least context. This post explains why SIEM-centric detection misses patient zero, and how prevalence-aware security analytics change the outcome.
Patient zero matters because everything that follows costs more. Lateral movement expands scope. Credential access increases blast radius. Exfiltration turns an incident into a crisis. Detect patient zero early, and you contain faster and investigate less.
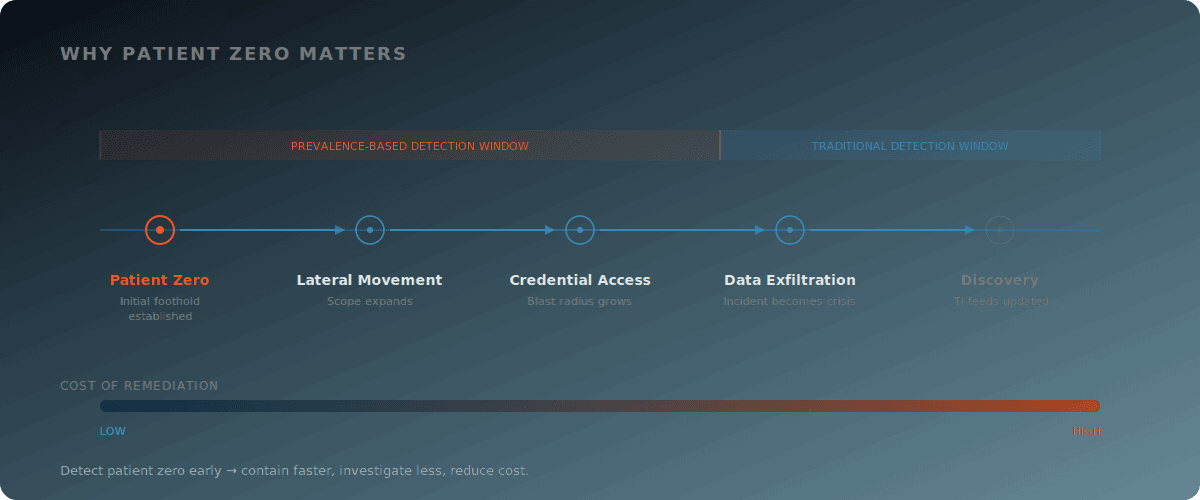
Why SIEM-Centric Detection Misses Patient Zero
Most detection programs depend on two inputs: telemetry inside the SIEM, and logic that searches that telemetry for known patterns. This model creates three bottlenecks that directly affect patient zero detection.
Costs scale with volume, not value
To detect rare activity, teams ingest high-volume telemetry. Audit logs, network flows, endpoint events, and application logs accumulate quickly. SIEM costs typically rise with ingestion and processing. That pressure forces tradeoffs: fewer sources, shorter retention, less enrichment, less deep analysis. Those tradeoffs reduce visibility into early-stage compromise.
Processing limits reduce analytic depth
After ingestion, teams face processing constraints. Enrichment and analytics often require additional services and paid APIs. At scale, the cost of enrichment becomes a reason not to enrich. The result is alerting without enough context to make decisions quickly.
If patient zero activity does not match a high-confidence signature, teams need richer analytics to spot it. That analytic depth rarely happens inside the SIEM because it is too expensive to run continuously at full volume.
Detection engineering becomes operationally fragile
Detection-as-code programs often start with a good idea: write detections once, manage them in version control, and deploy them consistently. In practice, many teams end up translating rules into multiple query languages and maintaining CI/CD pipelines that break when schemas, platforms, or data sources change.
That overhead reduces iteration speed. Patient zero detection depends on fast iteration because attackers change tradecraft faster than most teams can refactor detections.

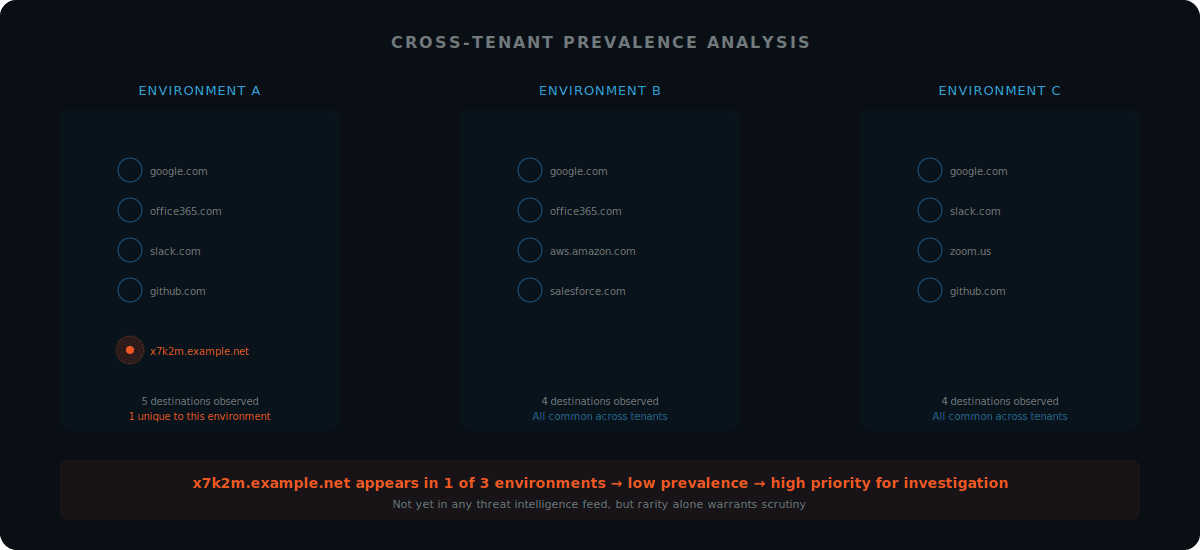
Cross-Tenant Prevalence: The Context Most Teams Lack
Patient zero detection needs a way to separate "unusual and important" from "unusual but benign." Prevalence provides that context.
Local prevalence measures how common an indicator is within your environment. Cross-tenant prevalence measures how common that indicator is across many customer environments.
Low-prevalence indicators can signal targeted activity. If a domain, IP, or traffic pattern appears in one customer environment and nowhere else, it deserves immediate scrutiny, even if it is not yet in threat intelligence feeds.
Many security teams operate without this external context. They can measure frequency internally, but they cannot easily determine whether an indicator is rare outside their perimeter. This increases triage time and raises the likelihood that patient zero remains hidden until the attacker creates obvious downstream activity.
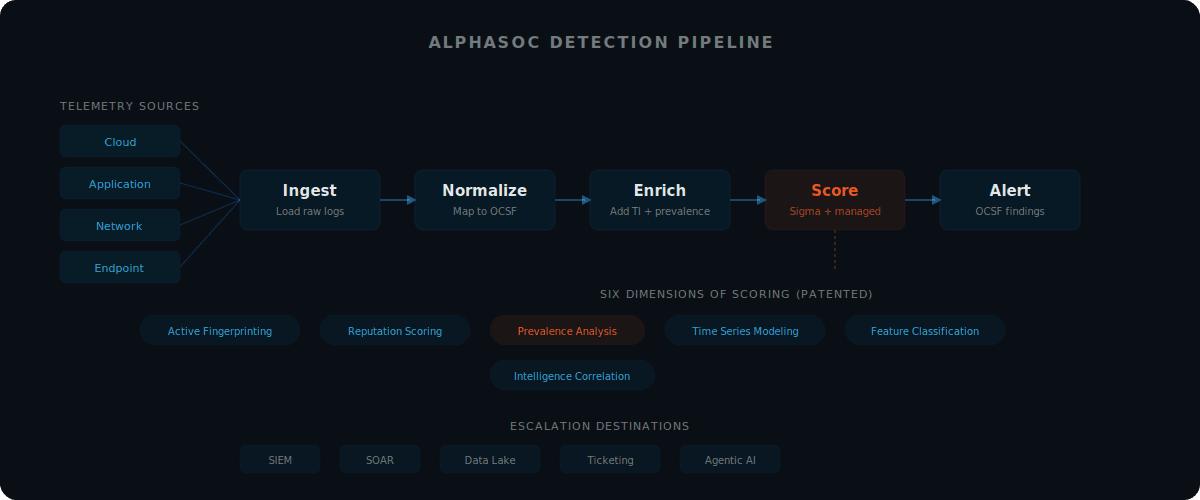
Detection Outside the SIEM Changes the Economics
To reduce cost and increase visibility, deep detection must happen outside the SIEM.
The goal is not to replace downstream tools. The goal is to shift detection logic left: move analytics to an engine that can process raw telemetry at scale, normalize it to OCSF, enrich it with threat intelligence and prevalence data, and escalate refined OCSF detection findings to the existing stack for triage.
This is a fundamentally different architecture from SIEM-centric detection. Instead of paying for indexing, storage, and query compute inside the SIEM, and then bolting on enrichment as an afterthought, the detection engine handles normalization, enrichment, and scoring upstream. The SIEM receives structured, high-confidence OCSF detection findings rather than raw telemetry that still needs processing.
AlphaSOC operates as this dedicated detection layer:
- Accepts telemetry from cloud, application, network, and endpoint sources, as well as data lakes, streaming platforms, and cloud storage
- Processes telemetry using a patented scoring stack that combines custom Sigma rules and managed AlphaSOC detections
- Normalizes all events to OCSF for consistent analysis
- Escalates OCSF detection findings with MITRE ATT&CK alignment to existing security tools for triage
This architecture supports patient zero detection because it enables deep processing without tying cost and performance to SIEM indexing constraints. Pricing is based on environment size, not data volume, so security teams can ingest everything without forced tradeoffs.
How AlphaSOC Surfaces Patient Zero Activity
AlphaSOC runs telemetry through six dimensions of scoring:
- Intelligence correlation against curated indicator sets from 70+ threat intelligence sources, housing 1M+ live, curated indicators
- Cross-tenant prevalence scoring to highlight traffic to rare destinations across customer environments
- Reputation scoring using external enrichment sources and sandboxing engines
- Anomaly detection through baselining and time series modeling to flag spikes, beaconing, and unusual patterns
- Feature classification to identify lookalike domains, DNS tunneling, and covert traffic patterns
- Active fingerprinting through an anonymizing proxy layer to identify command-and-control infrastructure in real time
These six dimensions reveal both known and unknown threats.

Known threats, confirmed faster
When telemetry matches known malicious infrastructure, AlphaSOC correlates against curated threat intelligence and enriches context automatically. This produces higher-confidence OCSF detection findings without requiring security teams to maintain enrichment pipelines inside their SIEM.
Unknown threats, surfaced by rarity and behavior
Patient zero often relies on infrastructure that has not yet appeared in public feeds. In those cases, prevalence and behavioral analysis highlight what is rare or abnormal.
Examples include:
- Lookalike domains used for spear phishing, identified through Certificate Transparency monitoring and network behavior
- Suspicious user behavior in applications such as Slack, GitHub, Salesforce, and 1Password
- Lateral movement and post-compromise activity detected through Sigma rules applied to endpoint telemetry
- Covert network activity such as DNS tunneling, ICMP tunneling, DNS-over-HTTPS, remote access tooling, and anonymizing protocols
In each case, early indicators are weak in isolation. Prevalence and the six dimensions of scoring provide the context needed to prioritize them.
Sigma Rules and Managed Detections
AlphaSOC natively supports Sigma rules. Sigma provides a portable detection format that teams can manage in version control and deploy through CI/CD pipelines. The Sigma community repository contains thousands of rules for Windows, macOS, Linux, cloud platforms, and applications.
Detections run consistently across telemetry sources without translation into multiple query languages. This reduces operational overhead and lowers the cost of experimentation. For patient zero detection, iteration speed determines whether new attack patterns are caught early or missed entirely.
In addition to custom Sigma rules, AlphaSOC provides managed detections aligned to MITRE ATT&CK, covering known threat actor tactics, techniques, and procedures. These managed detections run alongside custom rules and are continuously updated as new threats emerge.
Operational Impact: Full Visibility at Lower SIEM Cost
A patient zero detection program must improve visibility without increasing operational burden. This approach delivers three practical outcomes.
Full visibility without forced normalization up front. Raw telemetry is processed directly. AlphaSOC normalizes events to OCSF and escalates refined OCSF detection findings for triage, so security teams work with structured, enriched data without maintaining normalization pipelines.
Deeper analytics that surface attacker behavior. Compromised identities, endpoints, workloads, and suspicious egress patterns become visible earlier through cross-tenant prevalence analysis, active fingerprinting, and behavioral modeling. Intelligence correlation against 70+ sources and 1M+ live indicators means both known and unknown threats surface faster.
Reduced SIEM costs by shifting detection logic left. Large datasets no longer need to be ingested solely to support detection logic. Organizations can reduce SIEM costs by up to 80% while increasing coverage across cloud, application, network, and endpoint telemetry.
The workflow becomes simpler: send telemetry, run analytics at scale, escalate refined OCSF detection findings.
Conclusion
Patient zero is difficult to detect because most detection stacks optimize for known patterns and SIEM economics rather than rarity and early-stage compromise.
Security analytics that incorporate cross-tenant prevalence, enrichment, and anomaly detection change that equation. When low-prevalence infrastructure and suspicious behavior become visible, targeted attacks surface earlier.
AlphaSOC addresses this by running a detection engine outside the SIEM, applying Sigma rules and six dimensions of scoring, and escalating enriched OCSF detection findings for investigation. The result is earlier detection of both known and unknown threats across cloud, application, network, and endpoint telemetry.
Ready to detect patient zero? Get a demo or start a 30-day unrestricted evaluation.